
With the rapid growth of open LLMs, choosing the best one for a specific task has become quite daunting, especially if the performance cannot be easily quantified.
Moreover, existing rankings often average performance across multiple benchmarks, which can over-emphasize narrow use cases and miss broader practical applications.1 As such, I wanted to design and run a more open-ended benchmark with a straightforward interpretation.
Results#
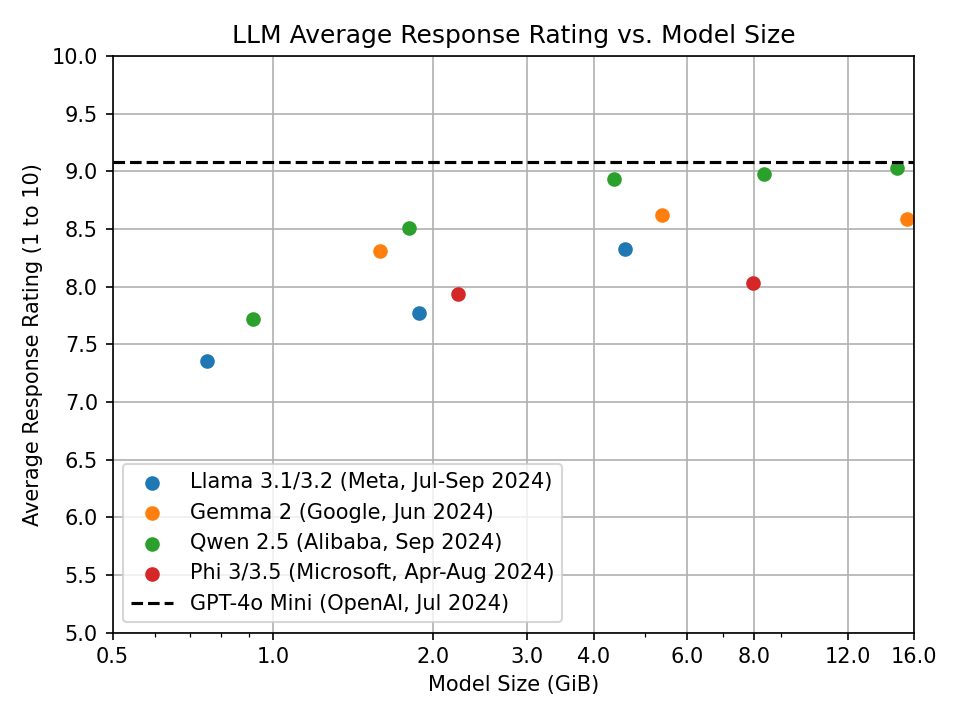
Here, we focus on popular models accessible to typical consumers, so the model size2 is capped at 16 GiB, which is the upper limit of VRAM available on most high-end consumer GPUs.3
While many systems offer more total RAM, using models larger than 16 GiB on CPUs can be slow enough to be frustrating to use.
Methodology#
Each LLM was evaluated using a set of 30 questions, with 3 trials per question. Responses were scored on a scale of 1 to 10 by OpenAI’s GPT-4o Mini.
The models tested in this benchmark include:
- Llama 3.2 (1B, 3B) and Llama 3.1 (8B) by Meta
- Gemma 2 (2B, 9B, 27B) by Google
- Phi 3.5 (3.8B) and Phi 3 (14B) by Microsoft
- Qwen 2.5 (1.5B, 3B, 7B, 14B, 32B) by Alibaba
All models were run with Q4_K_M quantization, except for qwen2.5:32b, which used Q3_K_M to fit within the 16 GiB
limit. Q4_K_M is a popular default because it significantly reduces memory usage without substantially impacting
output quality.
Importantly, using a consistent quantization avoids unfairly penalizing models with older or less optimal defaults.4
Question Set#
Six categories were selected, each with five short, open-ended questions ranging in difficulty from medium to extremely high.
- General Knowledge
- Mathematics
- Programming and Computer Science
- Language and Linguistics
- Creative Writing
- Ethics and Philosophy
Taking mathematics as an example, one of the easier questions is:
Calculate the sum of the first 20 prime numbers.
For comparison, a harder question is:
Let G be a non-abelian group of order 168, and let H be a subgroup of G of order 24; prove that the normalizer of H in G has order exactly 56.
Notably, many of the requests cannot be easily evaluated or scored, and thus would be overlooked by typical automated benchmarks.
See “Evaluating LLM Performance via LLM Judges” for the complete set of questions.
Judge Process#
OpenAI’s GPT-4o Mini evaluated each question-answer pair using a two-step process. In short, it was asked to
Analyze the question and generate its own answer.
This step allows the judge to “think” through the problem independently before evaluating the provided answer, helping to reduce bias and improve judgement quality.Rate the provided answer across five criteria: Correctness, Completeness, Clarity, Relevance, Conciseness.
Assign an overall score from 1 to 10.
See the “Evaluating LLM Performance via LLM Judges” for the additional instructions and exact prompt used in this process.
Is GPT-4o Mini an Impartial Judge?#
By design, LLMs are least perplexed by their own output, which could lead them to “prefer” their own responses during evaluation, even though they are not tagged with the name of the model that generated them.
To investigate this potential bias, I had Gemma 2 (27B) judge a random sample of 100 non-GPT and 25 GPT responses and compared its scores with GPT-4o Mini’s judgements.
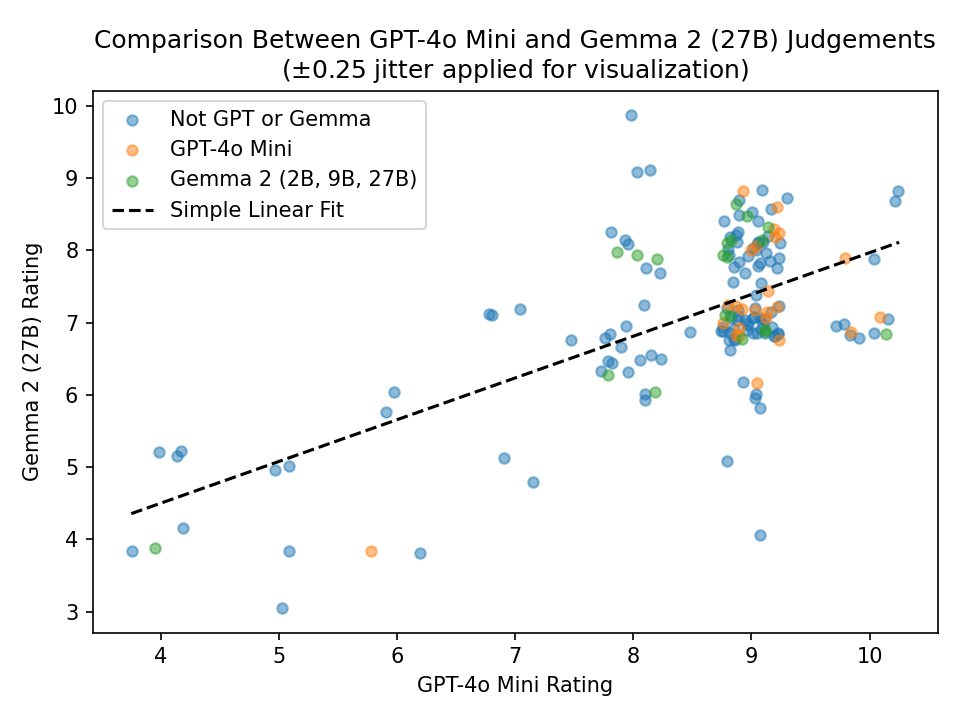
These results suggest that any systematic bias is minimal. After adjusting for Gemma’s tendency to give slightly lower ratings,
- 80% of the time, GPT-4o Mini and Gemma’s scores agree within 1/10.
- 95% of the time, their ratings are within 2/10.
Interestingly, GPT-4o Mini appears to be slightly more impartial than Gemma here.
- GPT-4o Mini rates its own responses +0.1/10 higher than Gemma’s ratings, on average.
- In contrast, Gemma rates its family’s responses +0.3/10 higher than GPT’s ratings, on average.
Why not use multiple judges?#
I initially considered aggregating ratings from multiple models, but the computational demands made this impractical for a simple experiment.5
Additionally, simultaneous prompt engineering across different models is highly challenging, to say the least. Techniques that work well with OpenAI’s models generally don’t transfer seamlessly to others.
Ultimately, using a single, well-calibrated judge like GPT-4o Mini strikes a decent balance between feasibility and meaningful results. Its analysis also (mostly) matches my own experience, making it a good starting point for a broad, interpretable comparison of model performance.
See also and references#
- The extra details in “Evaluating LLM Performance via LLM Judges” and links mentioned in the footnotes of this post.
- Hugging Face’s automated Open LLM Leaderboard, which provides a ranking that is fully reproducible and consistent between all models.
- Ollama, a common framework for locally running many of the publicly available LLMs.
- OpenAI’s Prompt Engineering Guidelines, which were used in creating and refining the LLM judge prompt in this experiment.
For example, Hugging Face’s Open LLM Leaderboard evaluates models by averaging several benchmarks on instruction following (IFEval), complex reasoning (BBH, MuSR), advanced math (MATH Level 5), graduate-level science questions (GPQA), and multi-domain multiple choice tasks (MMLU-PRO). ↩︎
Model size here refers to the size of the neural network parameters in memory, excluding additional memory required for inputs, outputs, and context. GiB (power-of-two gibibytes) are used to align with VRAM specifications. See this Wikipedia article for more details. ↩︎
According to the September 2024 Steam Hardware Survey, 84% of users have GPUs with 4-16 GiB of VRAM. The most common configurations are 8 GiB and 12 GiB. ↩︎
For instance, earlier models like Llama 3.1, Gemma 2, and Phi 3 default to the legacy
Q4_0quantization, which has a worse memory-to-quality trade-off. ↩︎The analysis in this post took more than a day of local computation, partially due to the use of an 8-year-old high-end GPU.
So, you can imagine how intensive an extra batch of \( (30 \text{ questions}) \cdot (3 \text{ trials per question}) \cdot (14 \text{ LLMs}) \cdot (2 \text{ queries per judge rating}) \cdot (n \text{ judges}) = 2520n \) additional evaluations would be.
I have run many multi-day experiments before, but simply outsourcing this process to OpenAI took mere minutes and cost a few cents. ↩︎


