
It’s easier than ever to run large language models (LLMs) like those behind ChatGPT on your local machine, without relying on third-party services. It’s free and keeps everything private and confidential!
Thanks to regular open-source releases from tech giants like Meta, Google, Microsoft, and Alibaba, powerful models are now widely available for public deployment and use.
In fact, there are impressively competent models that are lightweight enough to run on practically any smartphone. Notably, the recent “on-device” Llama 3.2 releases from Meta are only 1-2 GB in size. However, the larger models require increasingly expensive hardware to run properly.
For example, if I try to run a moderately-sized1 LLM on my budget $300 dev laptop with 8 GB of RAM2, I might get this.
$ ollama run qwen2.5:14b
Error: model requires more system memory (10.9 GiB) than is available (5.9 GiB)As the message says, all we need to do is add more system memory. But this doesn’t necessarily mean that we have to go out and upgrade our hardware.
“Adding” RAM from your disk: swap space#
If your disk is reasonably fast, you can generally offload some memory onto it, a process known as “swap” on Linux (the Windows keywords would be “increasing the size of the page file”). Swap space lets the kernel temporarily move inactive pages of memory to disk, freeing up RAM for other uses.
For example, these commands will temporarily add 8 GB of usable memory from the disk.3
sudo fallocate -l 8G /extra_swapfile # create an 8 GB file
sudo chmod 600 /extra_swapfile # make sure the file is only accessible by the root user
sudo mkswap /extra_swapfile # initialize the swap file
sudo swapon /extra_swapfile # activate and start using the swap fileWarning: This is honestly an abuse of swap and should not be regularly relied upon unless you are willing to drastically shorten your disk’s lifespan.
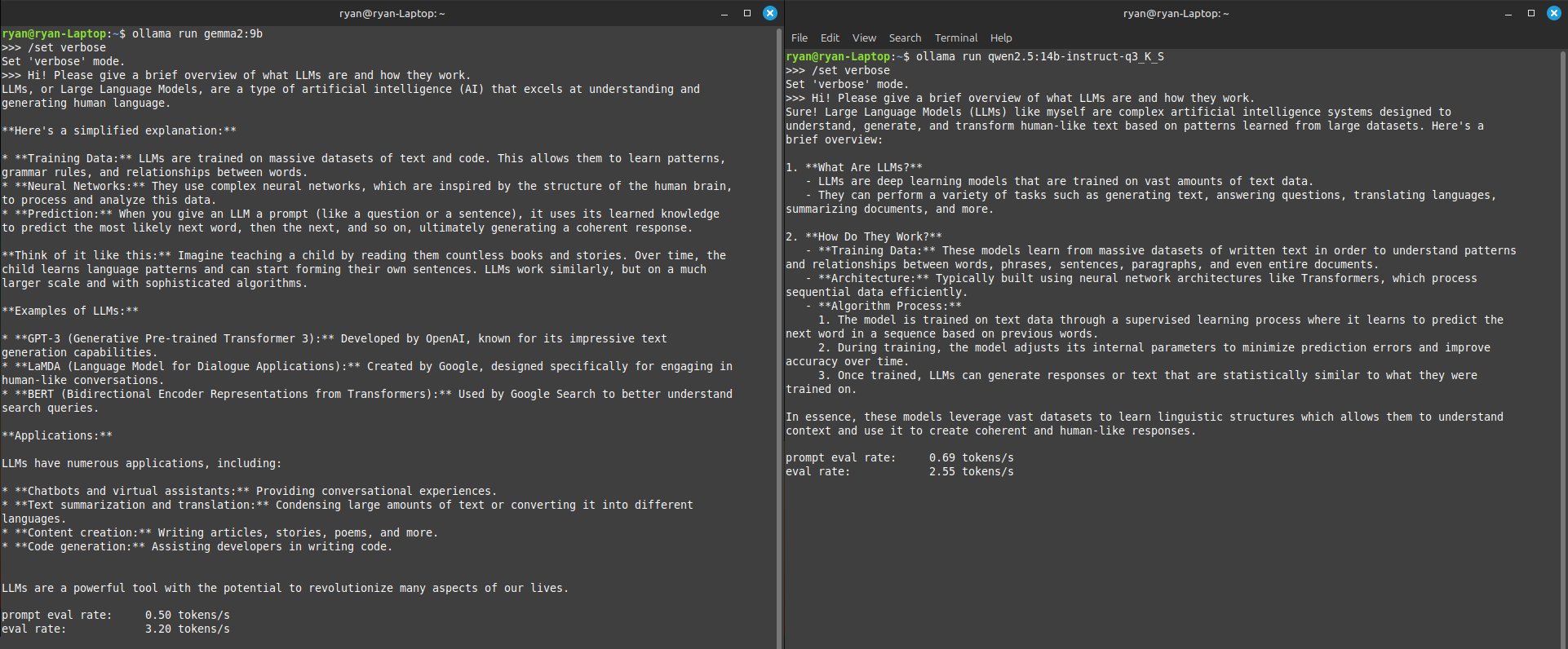
Afterward, you should be able to load the larger models without much trouble. Even on my incredibly cheap laptop, I am able to get 2-3 tokens/s (~100-150 words per minute) on 9B and 14B parameter models.4
This is extremely impressive for a machine that typically only has 5-6 GB of spare RAM!
EDIT (February 2025): Indeed, some users have successfully run the full 671B parameter Deepseek-R1 model off their SSDs, running at ~40-70 words per minute with under 64 GB of RAM! This is partially thanks to its mixture of experts (MoE) architecture where only ~37B parameters are activated during each forward pass, making it surprisingly well suited to this use case.
Obviously, this comes with the downside of worse performance since the system is thrashing. Each forward pass of the neural network involves shuffling data from disk to RAM and back.5
Simply put, if you need to effectively run an extra 1 GB of file transfers for every word the model generates, that takes a long time compared to having the model fit entirely in RAM.

As such, this can be useful in a pinch for experimentation, but you can only really scale this up as much as your patience would allow. Running significant portions of the model off disk necessarily means running the whole process several orders of magnitude slower than usual.
See also and references#
- Mozilla’s llamafile is probably the easiest way to get started with local LLMs. It packages all dependencies and model weights into a single executable, so it just takes a single click to run everything.
- Ollama is a very popular tool that provides more flexibility and customization for users comfortable with a small amount of extra setup.
- /r/LocalLLaMA, a Reddit community focused on local LLM usage, news, and experiences related to running LLMs on personal hardware.
- The Wikipedia article on thrashing, which is the term for this situation where we are constantly paging memory back and forth to disk. This is part of a broader memory management technique called virtual memory.
- A more in-depth experiment of mine from university on analyzing page faults through a custom Linux kernel module.
While 14 billion parameters might seem absurdly massive for most applications, this is indeed “moderately-sized” in the world of consumer-grade LLMs. Many users work with models in the 70B parameter range, which require at least 40 GB of spare memory across system RAM and GPU VRAM. ↩︎
Technically, this machine has 7 GB of usable system RAM since 1 GB is reserved for the APU, but it doesn’t matter much here. The key part is that this is a very low-end, secondary computer. ↩︎
To remove the swap file, you can simply run
sudo swapoff /extra_swapfileand delete it. To make the swap file persistent across boots, you’d add an entry into/etc/fstab. ↩︎Here, I’m using a slightly quantized version of Qwen2.5:14b, meaning the model size has been trimmed and reduced through various lossy optimizations. However, I was still able to run the default version at a much slower rate. ↩︎
CPUs generally cannot operate directly on data stored in swap directly. So, when the program needs data stored on disk, it has to first move some data from memory to disk, and then load the required data from disk back into memory. ↩︎


